こんにちは! hacknoteのr.katoです!
LambdaのLayerの使い方をこちらの記事で紹介しました。
しかし、headless chromeをLayerを使ってLambda関数で使う場合、若干複雑でしたので今回紹介していきます。
ファイルサイズが大きい物はLayerに投げます!
どういう事かと言いますと、Lambda関数にあげられるファイルサイズは50MBまで、そして大きいサイズのファイルをあげた場合コード編集不可という制約があります。
なので、zipにchromedriverなどを固めてLambda関数にあげてしまうとコードを変更することができなくなります。
一発勝負でコードを上げて100%バグなしで動きます!っていう人には関係のない話でかもしれませんが、Lambda関数の保存に時間がかかったりと非常にストレスがかかります。
そこでLayerにデータの大きいものは全て上げてしまって、Lambda関数にはコードだけ上げましょうという話です。
これが以前の形で
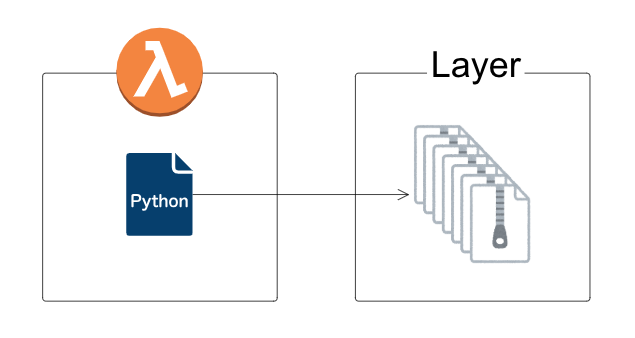
こちらが新しい形です
Layerの設定
Layerへの上げ方はこちらの記事を参照してください。
chromeはserverless-chromeを既に作成してくれた人がいますので、それを使います。
mkdir headless cd headless mkdir python cd python wget https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip mkdir bin unzip stable-headless-chromium-amazonlinux-2017-03.zip -d bin/ rm stable-headless-chromium-amazonlinux-2017-03.zip cd ../../ zip -r headless.zip ./headless
出来上がったheadless.zipをLayerに上げてください。
次のようにseleniumもzipに固め、Layerに上げてください。
もし、エラーが出るようであれば、Linux環境で作ってください。
mkdir selenium cd selenium mkdir python cd python pip install selenium -t . cd ../ zip -r selenium.zip ./python
lambda_function.py コード例
ここでは例としてhttps://www.google.comにアクセスしてtitleを返すようになっています。
※一応最後にdriver.qite()をする様にしてください。Lambdaではわかりませんが、macやwindowsなどのローカル環境で動かした場合、メモリ占有してしまいますので。
Lambdaの設定
こちらの記事を参考にLambdaにLayerを接続し、Lambdaの実行時間を1分ほどにし、メモリを320MBぐらいにし、上記のコードを入力し、実行すると次のようになりました。
無事、https://www.google.comにアクセスしてtitleを返してくれました。

さいごに
seleniumでheadless chromeをする時はchromedriverのPATHを”../bin/chromedriver”の様に指定していました。
しかし今回、Layerにchromedriverやserverless-chromeを上げた事で、PATHが”/opt/headless/python/bin/chromedriver”に変わっています。
Layerそのものが”/opt/”にあるため、この様な指定方法をしています。